Java io bufferedinputstream
Потоки ввода, InputStream
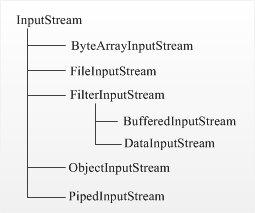
Существуют две параллельные иерархии классов ввода : InputStream и Reader. Класс Reader введен в последних версиях Java. В данной статье рассматривается вопрос использования потока байтового ввода InputStream, иерархия которого представлена на следующем рисунке.
Поток Stream— это абстрактное понятие источника или приёмника данных, которые способны обрабатывать информацию. Есть два типа потоков: байтовые и символьные. В некоторых ситуациях символьные потоки более эффективны, чем байтовые. Классы, производные от базовых InputStream или Reader, имеют методы read() для чтения отдельных байтов или массива байтов.
Входной поток InputStream
Базовый класс InputStream — это абстрактный класс, определяющий входной поток данных, и является родителем для классов, получающих данные из различных источников : массив байтов, строки (String), файлы, каналы pipe, у которых одна из сторон является входом, а вторая сторона играет роль выхода, и т.д. Методы класса InputStream при возникновении ошибки вызывают исключение IOException.
Методы класса InputStream :
| Метод | Описание |
|---|---|
| int read() | чтение одного байта; возвращает его целочисленное представление |
| boolean readBoolean() | чтение одного значения boolean |
| byte readByte() | чтение одного байта |
| char readChar() | чтение одного символ char |
| double readDouble() | чтение значения типа double |
| float readFloat() | чтение значения типа float |
| int readInt() | чтение целочисленного значения int |
| long readLong() | чтение значения типа long |
| short readShort() | чтение значения типа short |
| String readUTF() | чтение строки в кодировке UTF-8 |
| Object readObject() | чтение объекта |
| int skipBytes(int len) | пропуск при чтении нескольких байт, количество которых равно len |
| int available() | чтение количества доступных для чтения байт |
| void close() | закрытие потока |
Пример чтения объекта Person из файла :
Класс PipedInputStream
Класс PipedInputStream — это специальный класс, используемый для связи отдельных программ (потоков) друг с другом внутри одной JVM. Данный класс является важным инструментом организации синхронизации потоков.
Пример простого использования PipedInputStream :
Зачем BufferedInputStream, если InputStream предоставляет read с буфером
Зачем понадобилось включать в систему ввода-вывода Java обертку BufferedInputStream , если все реализации интерфейса InputStream по умолчанию содержат метод read(byte b[]) , в котором для чтения из потока используется буфер?
Для примера, написал программу, которая копирует видеофайл
100 мб из одного файла в другой.
Реализация с использованием BufferedInputStream :
Реализация с использованием метода read(byte b[])
Реализация с использованием класса BufferedInputStream работает примерно в 10 раз медленнее
1 ответ 1
Попробуйте сравнить скорость обработки с буферизацией и считыванием массива:
Полагаю, что скорость обработки будет сравнима со скоростью без буферизации, а может, даже быстрее, за счет другого размера буфера.
Почему первый пример работает медленно
Считывание/запись массива байтов из локального файла — очень быстрая операция. В лучше случае BufferedInputStream ( BufferedOutputStream ) не повлияет на производительность существенным образом, в худшем — производительность упадет из-за различных накладных расходов.
В вашем случае байты (
10^8) после считывания из буфера обрабатываются по одному, что сильно увеличивает накладные расходы:
- для каждого байта вызываются методы read и write — вызовы методов не бесплатны;
- хуже того, оба метода синхронизированные ( synchronized ) и при каждом вызове виртуальная машина выполняет переключение контекста/блокировку;
- в самих методах есть разнообразные проверки (открыт ли входной/выходной поток, закончился ли буфер и т.п.), которые также отнимают время.
Я полагаю, что основную нагрузку создает синхронизация. Можете для эксперимента добавить синхронизированные методы в вариант с FileInputStream
Зачем BufferedInputStream
Буферизированные потоки нужны чтобы не писать буферизацию самому. Также они позволяют отделить логику программы от настроек буферизации. BufferedInputStream особенно удобен если:
Используется алгоритм, который обрабатывает байты последовательно. В этом случае можно упростить код, доверив буферизацию встроенному классу.
Сам поток используется в качестве аргумента для класса-чтеца.
Например, BufferedInputStream можно передать в качестве аргумента Scanner :
После этого через Scanner можно будет работать с данными построчно, а BufferedInputStream сэкономит на обращениях к файловой системе.
Используются специфичные методы.
Методы InputStream.mark и InputStream.reset , как правило, недоступны в небуферизированных потоках. Соответственно, если потребуется откатывать состояние потока, то использовать FileInputStream не получится.
На примере с копированием файла преимущества увидеть сложно. С другой стороны, для копирования файла целесообразнее использовать встроенные методы, а не потоки.
Java.io.BufferedInputStream класс в Java
BufferedInputStream добавляет функциональность к другому входному потоку, а именно, возможность буферизовать ввод и поддерживать методы меток и сброса. При создании BufferedInputStream создается внутренний буферный массив. Поскольку байты из потока считываются или пропускаются, внутренний буфер пополняется по мере необходимости из содержащегося входного потока, много байтов за раз.
Конструктор и описание
- BufferedInputStream (InputStream in): создает BufferedInputStream и сохраняет его аргумент, входной поток, для дальнейшего использования.
- BufferedInputStream (InputStream in, int size): создает BufferedInputStream с указанным размером буфера и сохраняет его аргумент, входной поток, для последующего использования.
Методы:
- int available (): возвращает оценку количества байтов, которые
может быть прочитан (или пропущен) из этого входного потока без
блокировка при следующем вызове метода для этого входного потока. - void close (): закрывает этот входной поток и освобождает все системные ресурсы, связанные с этим потоком.
- void mark (int readlimit): отмечает текущую позицию в этом входном потоке.
- boolean markSupported (): Проверяет, поддерживает ли этот поток ввода методы mark и reset.
- int read (): читает следующий байт данных из входного потока.
- int read (byte [] b, int off, int len): считывает байты из этого потока байтового ввода в указанный байтовый массив, начиная с заданного смещения.
- void reset (): перемещает этот поток в позицию во время последнего вызова метода mark для этого входного потока.
- long skip (long n): пропускает и отбрасывает n байтов данных из этого входного потока
Программа:
// Java-программа для демонстрации работы BufferedInputStream
// Java-программа для демонстрации методов BufferedInputStream
public static void main(String args[]) throws IOException
// прикрепляем файл к FileInputStream
FileInputStream fin = new FileInputStream( «file1.txt» );
BufferedInputStream bin = new BufferedInputStream(fin);
// иллюстрирующий доступный метод
System.out.println( «Number of remaining bytes:» +
// иллюстрируем метод markSupported () и mark ()
// иллюстрирующий метод пропуска
/ * Исходное содержимое файла:
* Это моя первая строчка
* Это моя вторая строчка * /
// читаем символы из FileInputStream и
while ((ch=bin.read()) != — 1 )
System.out.print(( char )ch);
// иллюстрирующий метод reset ()
while ((ch=bin.read()) != — 1 )
System.out.print(( char )ch);
Эта статья предоставлена Nishant Sharma . Если вы как GeeksforGeeks и хотели бы внести свой вклад, вы также можете написать статью с помощью contribute.geeksforgeeks.org или по почте статьи contribute@geeksforgeeks.org. Смотрите свою статью, появляющуюся на главной странице GeeksforGeeks, и помогите другим вундеркиндам.
Пожалуйста, пишите комментарии, если вы обнаружите что-то неправильное или вы хотите поделиться дополнительной информацией по обсуждаемой выше теме.
Java BufferedInputStream Example
Posted by: Aldo Ziflaj in BufferedInputStream September 11th, 2014 0 Views
In this example we will discuss about BufferedInputStream class and its usage. The BufferedInputStream adds functionality to another input stream-namely, the ability to buffer the input and to support the mark and reset methods.
BufferedInputStream extends FilterInputStream , which simply overrides all methods of InputStream with versions that pass all requests to the contained input stream.
The BufferedInputStream class exists since JDK1.0.
The structure of BufferedInputStream
Constructor:
- BufferedInputStream(InputStream in) Creates a BufferedInputStream and saves its argument, the input stream in , for later use.
- BufferedInputStream(InputStream in, int size) Creates a BufferedInputStream with the specified buffer size, and saves its argument, the input stream in , for later use.
The BufferedInputStream in Java
To see a basic usage of the BufferedInputStream , create a class called SimpleBufferedInputStreamExample with the following source code:
I used the BufferedInputStream to read from a file and show the output of it in the console. Firstly, I created a BufferedInputStream instance from a FileInputStream . Then, I appended every char into a StringBuilder , to finally print it as a string.
In the end, don’t forget to close the BufferedInputStream instance.
The output of this program is:
This was the content of the file I read.
A better usage of BufferedInputStream
Just like in the above example, the BufferedInputStream can be used to get a response from a web service. To show how to do this, create a class called HttpClient in a webclient package:
This class creates a HTTP client. I only implemented the GET method, but the other methods implementation is similar. The get() method returns the response of the HTTP service into a string, and you can then parse this string with any method you would like.
To use this class, create a Main class and put this code into it:
I used a simple HTTP service, http://httpbin.org/, to test my HttpClient class.
When I send a GET request to get my IP address, it returns a JSON with the useful information. Then, you can use a JSON parser, like this one, to interpret the result.
My output here is:
More about the BufferedInputStream in Java
A BufferedInputStream adds functionality to another input stream-namely, the ability to buffer the input and to support the mark and reset methods. When the BufferedInputStream is created, an internal buffer array is created. As bytes from the stream are read or skipped, the internal buffer is refilled as necessary from the contained input stream, many bytes at a time. The mark operation remembers a point in the input stream and the reset operation causes all the bytes read since the most recent mark operation to be reread before new bytes are taken from the contained input stream.