Как правильно установить кодировку символов по умолчанию, используемую JVM (1.5.х) программно?
Я читал, что -Dfile.encoding=whatever раньше был способ пойти для старых JVMs. У меня нет такой роскоши по причинам, в которые я не хочу вдаваться.
и свойство устанавливается, но это, похоже, не вызывает окончательный вызов getBytes ниже, чтобы использовать UTF8:
15 ответов
к сожалению, file.encoding свойство должно быть указано при запуске JVM; к моменту ввода основного метода кодировка символов, используемая String.getBytes() и конструкторы по умолчанию InputStreamReader и OutputStreamWriter постоянно кэшируется.
As Эдвард грех указывает, в частном случае, как это, переменная окружения JAVA_TOOL_OPTIONS can используется для указания этого свойства, но обычно это делается так это:
Charset.defaultCharset() будет отражать изменения file.encoding свойство, но большинство кода в основных библиотеках Java, которые должны определить кодировку символов по умолчанию, не используют этот механизм.
когда вы кодируете или декодируете, вы можете запросить file.encoding собственность или Charset.defaultCharset() чтобы найти текущую кодировку по умолчанию и использовать соответствующий метод или перегрузку конструктора, чтобы указать ее.
поскольку командная строка не всегда может быть доступна или изменена, например, во встроенных VMs или просто VMs, запущенных глубоко в сценариях, a JAVA_TOOL_OPTIONS переменная предоставляется так, что агенты могут быть запущены в этих случаях.
установив переменную среды (Windows) JAVA_TOOL_OPTIONS до -Dfile.encoding=UTF8 , (Java) System свойство будет устанавливаться автоматически при каждом запуске JVM. Вы будет знать, что параметр был выбран, потому что следующее сообщение будет опубликовано на System.err :
Picked up JAVA_TOOL_OPTIONS: -Dfile.encoding=UTF8
У меня есть хакерский способ, который определенно работает!!
таким образом, вы собираетесь обмануть JVM, который будет думать, что charset не установлен и сделать это, чтобы установить его снова в UTF-8, во время выполнения!
Я думаю, что лучший подход, чем установка набора символов платформы по умолчанию, тем более, что у вас, похоже, есть ограничения на влияние на развертывание приложения, не говоря уже о платформе, — это вызвать гораздо более безопасный String.getBytes(«charsetName») . Таким образом, ваше приложение не зависит от вещей, находящихся вне его контроля.
Я лично считаю, что String.getBytes() должно быть устаревшим, так как это вызвало серьезные проблемы в ряде случаев, которые я видел, когда разработчик не учитывал значение по умолчанию кодировка, возможно, меняется.
Я не могу ответить на ваш первоначальный вопрос, но я хотел бы предложить вам несколько советов-не зависите от кодировки JVM по умолчанию. Всегда лучше явно указать желаемую кодировку (например,» UTF-8″) в вашем коде. Таким образом, вы знаете, что он будет работать даже в разных системах и конфигурациях JVM.
Picked up _JAVA_OPTIONS
Hello, We are using Solaris as a build machine. But have to set java temp directory per user. So we have added this line to .cshrc file. setenv _JAVA_OPTIONS -Djava.io.tmpdir=$HOME/tempdir
This changes temp dir as desired but, this will also shows Picked up _JAVA_OPTIONS: Djava.io.tmpdir=. message at console. java writes this message to stderr. How can i disable it ?
Because our ant script catch this message, ant thinks there is something wrong. Our build fails. We dont have a chance to change ant script. I tried everything, but i could not find a solution.
You’re not showing us the input so we don’t know what you’re doing. The output is what I’d expect to see if I typed in the «java» command with an inval >
Got idle CPU cycles? Join the war on COVID-19 by donating them to find the coronavirus’ weak spots. folding@home Runs in the background. https://foldingathome.org
Hello World Application
For those of you who want to follow along, let’s set up a test application, which we will use for debugging. If you already have your Java application running on OpenShift, you can jump ahead to the next section.
Let’s deploy a hello world application that I found on GitHub. This application was originally created to demonstrate how to build Vert.x-based microservices on OpenShift. You can get this application up and running in just two steps.
First, issue this command to build an S2I builder image for Vert.x applications:
OpenShift started the build of the builder image and you can follow the progress with:
At the end of the build process, OpenShift pushed the new image into the integrated Docker registry. Next, we are going to use the builder image to build and run a sample Vert.x application:
You can follow the build logs by issuing the command:
If everything went fine, you should be able to see the Hello world application running:
Enabling Debug and JMX Ports on JVM
In the following, I am going to use OpenJDK 1.8. Note that the available JVM options may vary depending on the version of the Java platform you are using.
To enable a remote debug port on JVM, one has to pass the following option to the JVM:
In order to enable JMX, the following JVM options are needed:
This set of options deserves a bit more explanation. By default, JMX utilizes RMI as the underlying technology for the communication between the JMX client and the remote JVM. And as a matter of fact, there are two RMI ports needed for this communication:
RMI registry port
RMI server port
At the beginning, the client connects to the RMI registry on port 3000 and looks up the connection to the RMI server. After the successful lookup, the client initiates a second connection to the RMI server. Based on our configuration, the client is going to connect to 127.0.0.1:3001. However, there’s no RMI server running on the local machine, so what’s the deal? As you will see in the next section, we are going to forward the local port 3001 back to the remote server.
Next, we need to convey our configuration options to the JVM running inside the OpenShift pod. It turns out that there exists an environment variable JAVA_TOOL_OPTIONS that is interpreted directly by the JVM and where you can put your JVM configuration options. I recommend using this variable as there is a great chance that this variable will work no matter how deep in your wrapper scripts you are launching the JVM. Go ahead and modify the DeploymentConfig or Pod descriptor of your application in OpenShift to add the JAVA_TOOL_OPTIONS variable. For example, you can open the DeloymentConfig for editing like this:
. and add the JAVA_TOOL_OPTIONS environment variable to the container section of the specification:
After applying the above changes, OpenShift will redeploy the application pod. At startup, JVM will print out the following line to the stderr which will show up in the container logs:
This verifies that our JVM options are in effect and the debug port and JMX ports are open. How are we going to connect to these ports? Let’s set up port forwarding on the local machine next.
Setting Up Port Forwarding
OpenShift features port forwarding that allows you to connect to an arbitrary port of a pod running on OpenShift. Port forwarding doesn’t require you to define any additional objects like Service or Route to enable it. What you need though is to start a port forwarding proxy on your local machine. Issue the following command on your local machine to start the proxy and forward the three ports 8000, 3000, and 3001 to the remote pod running on OpenShift:
In the above command, remember to replace
with the name of your application pod. If everything worked well, you should see the following output:
Note that the proxy keeps running on the foreground.
Attaching to the JVM running on OpenShift
Having our port-forwarding proxy all set, let’s fire up a debugger and attach it to our application. Note that we instruct the debugger to connect to the localhost on port 8000. This port is in turn forwarded to the port 8000 on the JVM:
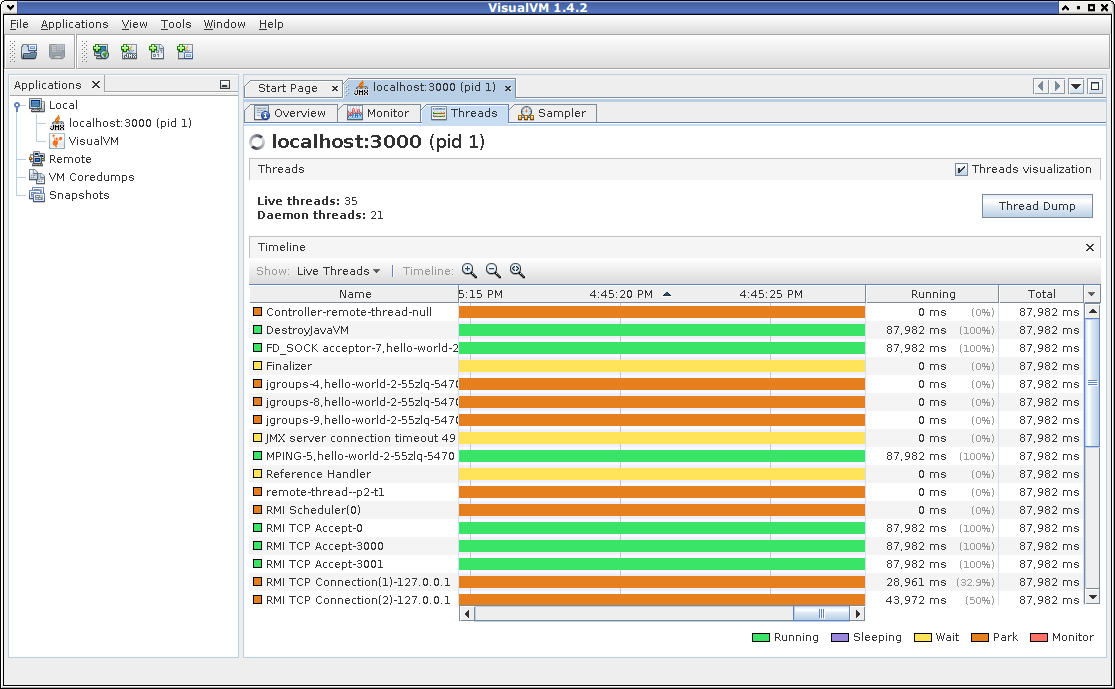
After the debugger attaches, you can list existing JVM threads using the threads command:
Next, let’s check out if we can attach VisualVM to our application as well:
Works like a charm, doesn’t it?
Conclusion
In this blog post, we were able to attach a debugger and VisualVM to the Java application running on OpenShift. We didn’t need to deploy Jolokia proxy or create additional Service or Route objects to make our setup work. Instead, we leveraged the port-forwarding feature already available in OpenShift. The demonstrated method has additional security benefits as we are not exposing any additional ports of the application container.
Hope you enjoyed this article and was able to reproduce this setup for yourself. If you have any thoughts or questions feel free to add them to the comment section below.
Java и Docker: это должен знать каждый
Многие разработчики знают, или должны знать, что Java-процессы, исполняемые внутри контейнеров Linux (среди них — docker, rkt, runC, lxcfs, и другие), ведут себя не так, как ожидается. Происходит это тогда, когда механизму JVM ergonomics позволяют самостоятельно задавать параметры сборщика мусора и компилятора, управлять размером кучи. Когда Java-приложение запускают без ключа, указывающего на необходимость настройки параметров, скажем, командой java -jar myapplication-fat.jar , JVM самостоятельно настроит некоторые параметры, стремясь обеспечить наилучшую производительность приложения. В этом материале мы поговорим о том, что необходимо знать разработчику перед тем, как он займётся упаковкой своих приложений, написанных на Java, в контейнеры Linux.
Мы рассматриваем контейнеры в виде виртуальных машин, настраивая которые можно задать число виртуальных процессоров и объём памяти. Контейнеры больше похожи на механизм изоляции, где ресурсы (процессор, память, файловая система, сеть, и другие), выделенные некоему процессу, изолированы от других. Подобная изоляция возможна благодаря механизму ядра Linux cgroups.
Надо отметить, что некоторые приложения, которые при работе полагаются на данные, полученные из среды выполнения, созданы до появления cgroups. Утилиты вроде top , free , ps , и даже JVM, не оптимизированы для исполнения внутри контейнеров, фактически — сильно ограниченных процессов Linux. Посмотрим, что происходит, когда программы не учитывают особенности работы в контейнерах и выясним, как избежать ошибок.
В демонстрационных целях я создал демон docker в виртуальной машине с 1 Гб ОЗУ, используя такую команду:
Далее, я выполнил команду free -h в трёх различных дистрибутивах Linux, исполняющихся в контейнере, использовав ограничения в 100 Мб, заданные ключами -m и —memory-swap . В результате все они показали общий объём памяти в 995 Мб.
Результаты выполнения команды free -h
Похожий результат получается даже в кластере Kubernetes / OpenShift. Я запустил группу контейнеров Kubernetes с ограничением памяти, используя такую команду:
При этом кластеру было назначено 15 Гб памяти. В итоге общий объём памяти, о котором сообщила система, составил 14 Гб.
Исследование кластера с 15 Гб памяти
Для того, чтобы понять причины происходящего, советую прочесть этот материал об особенностях работы с памятью в контейнерах Linux.
Надо понимать, что ключи Docker ( -m, —memory и —memory-swap ), и ключ Kubernetes ( —limits) указывают ядру Linux на необходимость остановки процесса, если он пытается превысить заданный лимит. Однако, JVM ничего об этом не знает, и когда она выходит за рамки подобных ограничений, ничего хорошего ждать не приходится.
Для того, чтобы воспроизвести ситуацию, в которой система останавливает процесс после превышения заданного лимита памяти, можно запустить WildFly Application Server в контейнере с ограничением памяти в 50 Мб, воспользовавшись такой командой:
Теперь, в процессе работы контейнера, можно выполнить команду docker stats для того, чтобы проверить ограничения.
Данные о контейнере
Через несколько секунд исполнение контейнера WildFly будет прервано, появится сообщение:
Выполним такую команду:
Она сообщит о том, что контейнер был остановлен из-за возникновения ситуации OOM (Out Of Memory, нехватка памяти). Обратите внимание на то, что состояние контейнера — это OOMKilled=true .
Анализ причины остановки контейнера
Влияние неверной работы с памятью на Java-приложения
В демоне Docker, который исполняется на машине с 1 ГБ памяти (ранее созданной командой docker-machine create -d virtualbox –virtualbox-memory ‘1024’ docker1024 ), но с памятью контейнера, ограниченной 150-ю мегабайтами, что кажется достаточным для приложения Spring Boot, приложение Java запускается с параметрами XX:+PrintFlagsFinal и -XX:+PrintGCDetails , заданными в Dockerfile. Это позволяет нам прочесть исходные параметры механизма JVM ergonomics и узнать подробности о запусках сборки мусора (GC, Garbage Collection).
Попробуем это сделать:
Я подготовил конечную точку по адресу /api/memory/ , которая загружает в память JVM строковые объекты для имитации операции, потребляющей большой объём памяти. Выполним такой вызов:
Конечная точка ответит примерно следующим образом:
Всё это может навести нас, по меньшей мере, на два вопроса:
Почему размер максимальной разрешённой памяти JVM равен 241.7 МиБ?
Если ограничение памяти контейнера составляет 150 Мб, почему он позволил Java выделить почти 220 Мб?
Для того, чтобы с этим разобраться, сначала надо вспомнить, что говорится о максимальном размере кучи (maximum heap size) в документации по JVM ergonomics. Там сказано, что максимальный размер кучи составляет 1/4 размера физической памяти. Так как JVM не знает, что исполняется в контейнере, максимальный размер кучи будет близок к 260 Мб. Учитывая то, что мы добавили флаг -XX:+PrintFlagsFinal при инициализации контейнера, можно проверить это значение:
Теперь надо понять, что когда в командной строке Docker используется параметр — m 150M , демон Docker ограничит размеры памяти и swap-файла 150-ю мегабайтами. В результате процесс сможет выделить 300 мегабайт, что и объясняет, почему наш процесс не получил сигнал KILL от ядра Linux.
Об особенностях различных комбинаций параметров ограничения памяти ( —memory ) и swap-файла ( —swap ) в командной строке Docker можно почитать здесь.
Увеличение объёма памяти как пример неверного решения проблемы
Разработчики, не понимающие сути происходящего, склонны полагать, что вышеописанная проблема заключается в том, что окружение не даёт достаточно памяти для исполнения JVM. В результате частое решение этой проблемы заключается в увеличении объёма доступной памяти, но такой подход, на самом деле, только ухудшает ситуацию.
Предположим, мы предоставили демону не 1 Гб памяти, а 8 Гб. Для его создания подойдёт такая команда:
Следуя той же идее, ослабим ограничение контейнера, дав ему не 150, а 800 Мб памяти:
Обратите внимание на то, что команда curl http://`docker-machine ip docker8192`:8080/api/memory в таких условиях даже не сможет выполниться, так как вычисленный параметр MaxHeapSize для JVM в окружении с 8 Гб памяти будет равен 2092957696 байт (примерно 2 Гб). Проверить это можно такой командой:
Проверка параметра MaxHeapSize
Приложение попытается выделить более 1.6 Гб памяти, что больше, чем лимит контейнера (800 Мб RAM и столько же в swap-файле), в результате процесс будет остановлен.
Ясно, что увеличение объёма памяти и позволение JVM устанавливать собственные параметры — далеко не всегда правильно при выполнении приложений в контейнерах. Когда Java-приложение исполняется в контейнере, мы должны устанавливать максимальный размер кучи самостоятельно (с помощью параметра —Xmx ), основываясь на нуждах приложениях и ограничениях контейнера.
Верное решение проблемы
Небольшое изменение в Dockerfile позволяет нам задавать переменную окружения, которая определяет дополнительные параметры для JVM. Взгляните на следующую строку:
Теперь можно использовать переменную окружения JAVA_OPTIONS для того, чтобы сообщать системе о размере кучи JVM. Этому приложению, похоже, хватит 300 Мб. Позже можно взглянуть в логи и найти там значение 314572800 байт (300 МиБ).
Задавать переменные среды для Docker можно, используя ключ -e :
В Kubernetes переменную среды можно задать, воспользовавшись ключом –env=[key=value] :
Улучшаем верное решение проблемы
Что если размер кучи можно было бы рассчитать автоматически, основываясь на ограничениях контейнера?
Это вполне достижимо, если использовать базовый образ Docker, подготовленный сообществом Fabric8. Образ fabric8/java-jboss-openjdk8-jdk задействует скрипт, который выясняет ограничения контейнера и использует 50% доступной памяти как верхнюю границу. Обратите внимание на то, что вместо 50% можно использовать другое значение. Кроме того, этот образ позволяет включать и отключать отладку, диагностику, и многое другое. Взглянем на то, как выглядит Dockerfile для приложения Spring Boot:
Теперь всё будет работать так, как нужно. Независимо от ограничений памяти контейнера, наше Java-приложение всегда будет настраивать размер кучи в соответствии с параметрами контейнера, не основываясь на параметрах демона.
Использование разработок Fabric8
Итоги
JVM до сих пор не имеет средств, позволяющих определить, что она выполняется в контейнеризированной среде и учесть ограничения некоторых ресурсов, таких, как память и процессор. Поэтому нельзя позволять механизму JVM ergonomics самостоятельно задавать максимальный размер кучи.
Один из способов решения этой проблемы — использование образа Fabric8 Base, который позволяет системе, основываясь на параметрах контейнера, настраивать размер кучи автоматически. Этот параметр можно задать и самостоятельно, но автоматизированный подход удобнее.
В JDK9 включена экспериментальная поддержка JVM ограничений памяти cgroups в контейнерах (в Docker, например). Тут можно найти подробности.
Надо отметить, что здесь мы говорили о JVM и об особенностях использования памяти. Процессор — это отдельная тема, вполне возможно, мы ещё её обсудим.
Уважаемые читатели! Сталкивались ли вы с проблемами при работе с Java-приложениями в контейнерах Linux? Если сталкивались, расскажите пожалуйста о том, как вы с ними справлялись.






 would look like this:</p><p>Note the double quotes. Single quotes wouldn’t work right (no variable substitution), I <i>think</i> for this kind of declaration quotes may be omitted, but this is the safe way.</p><p>Got idle CPU cycles? Join the war on COVID-19 by donating them to find the coronavirus’ weak spots. folding@home Runs in the background. https://foldingathome.org</p><p>Ok, <br />I think _JAVA_OPTIONS environment variable, is a special environment variable, which jvm looks for when it is initialized. <br />It does not have to be solaris. I tried in windows too. I have defined _JAVA_OPTIONS environment variable and then i typed java at windows console. <br />Ok everything is normal except Picked up message. Can not java be stay silent ? Does it have to say, what did it picked up. <br />Output is: <br />Picked up _JAVA_OPTIONS: -Djava.io.tmpdir=»C:temp» <br />Usage: java [-options] class [args. ] <br />(to execute a class) <br />or java [-options] -jar jarfile [args. ] <br />(to execute a jar file)</p><p>where options include: <br />-client to select the «client» VM <br />-server to select the «server» VM <br />-hotspot is a synonym for the «client» VM [deprecated] <br />The default VM is client.</p><p>-cp <br />-classpath <br />A ; separated list of directories, JAR archives, <br />and ZIP archives to search for class files. <br />-D = <br />set a system property <br />-verbose[:class|gc|jni] <br />enable verbose output <br />-version print product version and exit <br />-version: <br />require the specified version to run <br />-showversion print product version and continue <br />-jre-restrict-search | -jre-no-restrict-search <br />include/exclude user private JREs in the version search <br />-? -help print this help message <br />-X print help on non-standard options <br />-ea[:</p><p>. |: ] <br />disable assertions <br />-esa | -enablesystemassertions <br />enable system assertions <br />-dsa | -disablesystemassertions <br />disable system assertions <br />-agentlib:</li><li>[= ] <br />load native agent library</li><li>, e.g. -agentlib:hprof <br />see also, -agentlib:jdwp=help and -agentlib:hprof=help <br />-agentpath:</p><p>[= ] <br />load native agent library by full pathname <br />-javaagent: [= ] <br />load Java programming language agent, see java.lang.instrument</p><p>-splash: <br />show splash screen with specified image</p><p style=)

; <br />In .cshrc file I have set <br />setenv TMPDIR «/users/u6/myusername/tempdir»</p><p>but System.getProperty(«java.io.tmpdir»); still gives /var/tmp/ <br />I dont understand how System.getProperty(«java.io.tmpdir»); decide which directory is temp directory ? How can i edit it. <br />by the way i cannot use -Djava.io.tmpdir</p><p style=)
 on the java command line, you may be stuck with the default temporary directory location.</p><p>Got idle CPU cycles? Join the war on COVID-19 by donating them to find the coronavirus’ weak spots. folding@home Runs in the background. https://foldingathome.org</p><p>Why is this working on window ? <br />In windows TEMP and TMP environment variables are set to D:ProfilesmyusernameLocal SettingsTemp <br />When I call «java Test» <br />Output is : temdir->>D:ProfilesmyusernameLocal SettingsTemp</p><p>I am changing TEMP and TMP to C:tesdir <br />Then again I am calling «java Test» <br />Output is : temdir->>c:testdir</p><p style=)
 of Windows you’re talking about. Originally — as the Javadocs indicate — the most common location for tempfiles was in C:temp or sometimes C:tmp. However, somewhere around Windows XP they tried to re-invent the Unix idea of a /home directory but with a cute Microsoft name (containing embedded spaces so as to confuse command-line parsers). One thing you should note is that implicit in your illustration is that each user would have a distinct temp directory. When you’re talking things like servers that are shared across users, you can end up with NTFS file access rights problems. Plus, I’m nut sure who normally has write rights to the «All Users» user directory on versions of Windows that have such a thing.</p><p>2. As far as I know, there’s no TEMP/TMP environment variable convention at all on Unix/Linux. Individual apps can do whatever they want, but there’s no master setting. In Unix and Linux, environments are propagated and shared or created from scratch depending on the options used to spawn the process or subprocess. On my machines, neither TMP nor TEMP were ever set at all. And, of course, since there’s no enforcement on such things, if someone wanted to set TEMP to a string that was unrelated to a file system location, there’s nothing to prevent it, but a Java app that didn’t know about it would encounter difficulties, breaking the «write once/run anywhere» rule.</p><p>I never argue with success. Or at least I try not to as long as it’s not illegal, immoral or lacks redeeming features. So if you can get what you want by setting an environment variable, be my guest. All I can say is that it’s not a mechanism that you can count on to run reliably at all times and in all places.</p><p>Sun has their own official Java forums. I don’t hang out there because they are high traffic and unlike the JavaRanch, they don’t have a no-flaming policy. But if you want a definitive answer, ask there. I’m quoting the docs, but the docs are based on what they actually decide. Let us know what they say!</p><h2>Remote Debugging of Java Applications on OpenShift</h2><h3>Learn more about remote debugging on Java applications with OpenShift.</h3><p>Join the DZone community and get the full member experience.</p><p>In this article, I am going to show you how to attach a debugger and a VisualVM profiler to the Java application running on OpenShift. The approach described here doesn’t make use of the Jolokia bridge. Instead, we are going to leverage the port-forwarding feature of OpenShift.</p><p>The whole setup can be divided into three steps:</p><ol><li>Enable debug and JMX ports on the JVM</li><li>Set up port forwarding</li><li>Attach debugger and VisualVM to the forwarded ports</li></ol><p>I am going to use OpenShift v3.11 that I installed using Minishift and a test application built with Java OpenJDK 1.8. This is how the complete setup is going to look like:</p><div style=)