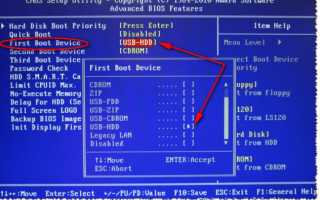
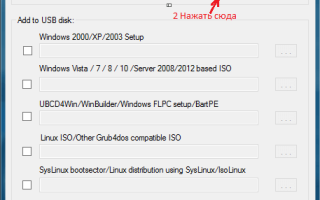
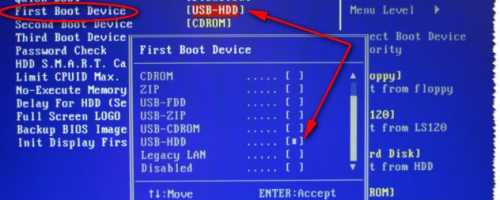
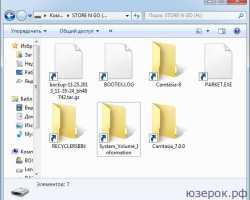
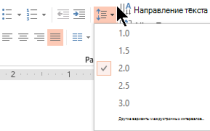
Winsetupfromusb как создать загрузочную флешку xp Установка Windows XP с флешки с помощью WinSetupFromUSB Итак, перед нами поставлена задача, создать...
Одноклассники моя страница вход бесплатно войти Одноклассники моя страница Одноклассники моя страница — это ваш аккаунт в социальной сети Одноклассники....
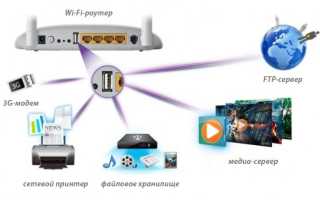
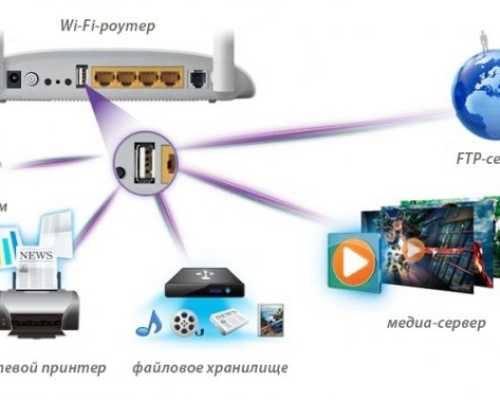
Сетевой диск через роутер Подключение жесткого диска к роутеру: инструкции для разных маршрутизаторов В квартире много устройств, которым требуется соединение...