


Java regexp replace
Обработка строк в Java. Часть II: Pattern, Matcher
Вступление
Что Вы знаете о обработке строк в Java? Как много этих знаний и насколько они углублены и актуальны? Давайте попробуем вместе со мной разобрать все вопросы, связанные с этой важной, фундаментальной и часто используемой частью языка. Наш маленький гайд будет разбит на две публикации:
- String, StringBuffer, StringBuilder (реализация строк)
- Pattern, Matcher (регулярные выражения)
Сегодня поговорим о регулярных выражениях в Java, рассмотрим их механизм и подход к обработке. Также рассмотрим функциональные возможности пакета java.util.regex.
Регулярные выражения
Большинство современных языков программирования поддерживают РВ, Java не является исключением.
Механизм
Существует две базовые технологии, на основе которых строятся механизмы РВ:
- Недетерминированный конечный автомат (НКА) — «механизм, управляемый регулярным выражением»
- Детерминированный конечный автомат (ДКА) — «механизм, управляемый текстом»
НКА — механизм, в котором управление внутри РВ передается от компонента к компоненту. НКА просматривает РВ по одному компоненту и проверяет, совпадает ли компонент с текстом. Если совпадает — проверятся следующий компонент. Процедура повторяется до тех пор, пока не будет найдено совпадение для всех компонентов РВ (пока не получим общее совпадение).
ДКА — механизм, который анализирует строку и следит за всеми «возможными совпадениями». Его работа зависит от каждого просканированного символа текста (то есть ДКА «управляется текстом»). Даний механизм сканирует символ текста, обновляет «потенциальное совпадение» и резервирует его. Если следующий символ аннулирует «потенциальное совпадение», то ДКА возвращается к резерву. Нет резерва — нет совпадений.
Логично, что ДКА должен работать быстрее чем НКА (ДКА проверяет каждый символ текста не более одного раза, НКА — сколько угодно раз пока не закончит разбор РВ). Но НКА предоставляет возможность определять ход дальнейших событий. Мы можем в значительной степени управлять процессом за счет правильного написания РВ.
Регулярные выражения в Java используют механизм НКА.
Эти виды конечных автоматов более детально рассмотрены в статье «Регулярные выражения изнутри».
Подход к обработке
В языках программирования существует три подхода к обработке РВ:
- интегрированный
- процедурный
- объектно-ориентированный
Интегрированный подход — встраивание РВ в низкоуровневый синтаксис языка. Этот подход скрывает всю механику, настройку и, как следствие, упрощает работу программиста.
Функциональность РВ при процедурном и объектно-ориентированном подходе обеспечивают функции и методы соответственно. Вместо специальных конструкций языка, функции и методы принимают в качестве параметров строки и интерпретируют их как РВ.
Для обработки регулярных выражений в Java используют объектно-ориентированный подход.
Реализация
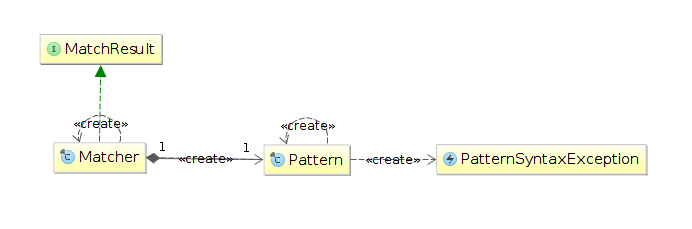
Pattern
Класс Pattern представляет собой скомпилированное представление РВ. Класс не имеет публичных конструкторов, поэтому для создания объекта данного класса необходимо вызвать статический метод compile и передать в качестве первого аргумента строку с РВ:
Также в качестве второго параметра в метод compile можно передать флаг в виде статической константы класса Pattern, например:
Таблица всех доступных констант и эквивалентных им флагов:
| № | Constant | Equivalent Embedded Flag Expression |
|---|---|---|
| 1 | Pattern.CANON_EQ | — |
| 2 | Pattern.CASE_INSENSITIVE | (?i) |
| 3 | Pattern.COMMENTS | (?x) |
| 4 | Pattern.MULTILINE | (?m) |
| 5 | Pattern.DOTALL | (?s) |
| 6 | Pattern.LITERAL | — |
| 7 | Pattern.UNICODE_CASE | (?u) |
| 8 | Pattern.UNIX_LINES | (?d) |
Иногда нам необходимо просто проверить есть ли в строке подстрока, что удовлетворяет заданному РВ. Для этого используют статический метод matches, например:
Также иногда возникает необходимость разбить строку на массив подстрок используя РВ. В этом нам поможет метод split:
Matcher и MatchResult
Matcher — класс, который представляет строку, реализует механизм согласования (matching) с РВ и хранит результаты этого согласования (используя реализацию методов интерфейса MatchResult). Не имеет публичных конструкторов, поэтому для создания объекта этого класса нужно использовать метод matcher класса Pattern:
Но результатов у нас еще нет. Чтобы их получить нужно воспользоваться методом find. Можно использовать matches — этот метод вернет true только тогда, когда вся строка соответствует заданному РВ, в отличии от find, который пытается найти подстроку, которая удовлетворяет РВ. Для более детальной информации о результатах согласования можно использовать реализацию методов интерфейса MatchResult, например:
Регулярные выражения Java
View more Tutorials:
1- Регулярные выражения (Regular expression)
Регулярное выражение (regular expression) определяет шаблон (pattern) поиска для строк. Регулярные выражения могут использоваться для поиска, редактирования и манипулирования текстом. Шаблон, определенный регулярным выражением, может совпадать один или несколько раз, или не совпадает с данным текстом.
Аббревиатурой для регулярного выражения является регулярное выражение.
Возможно вам будет интересно:
2- Принцип написания регулярного выражения
| No | Регулярные выражения | Описание |
| 1 | . | Подходит (match) любому символу |
| 2 | ^regex | Регулярное выражение должно совпасть с начального пункта |
| 3 | regex$ | Регулярное выражение должно совпасть в конце строки. |
| 4 | [abc] | Создание определения, может подойти к a или b или c. |
| 5 | [abc][vz] | Создание определения, может подойти к a или b или c, затем следует v или z. |
| 6 | [^abc] | Когда появляется знак ^ как первый символ в квадратных скобках, он опровергает модель. Это может совпасть с любым символом, кромер a или b или c. |
| 7 | [a-d1-7] | Рамки: подходит к строке между a и пунктом d и числом от 1 до 7. |
| 8 | X|Z | Поиск X или Z. |
| 9 | XZ | Поиск X а затем Z. |
| 10 | $ | Проверка завершения строки. |
| 11 | d | Любое число, краткая форма [0-9] |
| 12 | D | Символ неявляющийся числом, краткая форма [^0-9] |
| 13 | s | Символ пробела, краткая форма [ tnx0brf] |
| 14 | S | Символ неявляющийся пробелом, краткая форма [^s] |
| 15 | w | Символ букв, краткая форма [a-zA-Z_0-9] |
| 16 | W | Символ неявляющийся пробелом, краткая форма [^w] |
| 17 | S+ | Некоторые символы неявляющиеся пробелом (Один или более) |
| 18 | b | Символ яляется a-z или A-Z или 0-9 или _, краткая форма [a-zA-Z0-9_] . |
| 19 | * | Появляется 0 или много раз, краткая форма |
| 20 | + | Появляется 1 или много раз, краткая форма |
| 21 | ? | Появляется 0 или 1 раз, ? краткая форма <0,1>. |
| 22 | Появляется X раз, <> | |
| 23 | Появляется от X до Y раз. | |
| 24 | *? | * значит появляется 0 или много раз, добавление ? в конце значит поиск самого маленького совпадения. |
3- Специальные символы в Java Regex (Special characters)
Символы, перечисленные выше, являются специальными символами. В Java Regex если вы хотите, чтобы он понял этот символ обычным способом, вы должны добавить впереди.
Например сивол точки. Java regex понимает как любой символ, если вы хотите, чтобы он понимал как символ обычной точки, требуется знак впереди.
4- Использование String.matches(String)
- Class String



5- Использование Pattern и Matcher
1. Pattern это модельный объект, скомпилированная версия регулярного выражения. Он не имеет никакого публичного конструктора (constructor), и мы используем статический метод compile(String) для создания объекта, с аргументом регулярного выражения.
2. Matcher это способ сравнения совпадения вводной строки данных с созданным выше объектом Pattern. Этот класс не имеет публичный конструктор, и мы можем взять эот объект через метод matcher(String) обхекта Pattern. С вводным аргументом String являющимся документом для проверки.
3. Выражение PatternSyntaxException выбрасывается, если синтаксис регулярных выражений неверен.
Регулярные выражения java примеры
Java предоставляет пакет java.util.regex для сопоставления с шаблоном с регулярными выражениями. Регулярные выражения Java очень похожи на язык программирования Perl и очень просты в освоении.
Регулярное выражение(regular expressions) — это специальная последовательность символов, которая помогает вам сопоставлять или находить другие строки или наборы строк, используя специальный синтаксис, содержащийся в шаблоне. Их можно использовать для поиска, редактирования или манипулирования текстом и данными.
Шаблон поиска может быть любым из простого символа, фиксированной строки или сложного выражения, содержащего специальные символы, описывающие шаблон. Шаблон, определенный выражением, может совпадать один или несколько раз или не совпадать для данной строки.
Шаблон применяется к тексту слева направо. Как только исходный символ был найден, его нельзя уже использовать повторно. Например, выражение aba будет соответствовать ababababa только два раза (aba_aba__)
Пакет java.util.regex в основном состоит из следующих трех классов:
- Класс Pattern — Объект Pattern представляет собой скомпилированное представление регулярного выражения. Класс Pattern не предоставляет общедоступных конструкторов. Чтобы создать шаблон, вы должны сначала вызвать один из его открытых статических методов compile(), который затем вернет объект Pattern. Эти методы принимают выражение в качестве первого аргумента.
- Класс Matcher — объект Matcher — это механизм, который интерпретирует шаблон и выполняет операции сопоставления с входной строкой. Как и класс Pattern, Matcher не определяет общедоступных конструкторов. Вы получаете объект Matcher, вызывая метод matcher() для объекта Pattern.
- PatternSyntaxException — Объект PatternSyntaxException является непроверенным исключением, которое указывает на синтаксическую ошибку в образце выражения.
Простым примером является строка. Например, Hello World соответствует строке «Hello World». , (точка) является еще одним примером. Точка соответствует любому отдельному символу; будет соответствовать, например, «а» или «1».
| выражение | соответствие |
|---|---|
| это текст | соответствует «это текст» |
| thiss+iss+text | Соответствует слову «this», за которым следуют один или несколько пробелов, за которыми следует слово «is», за которыми следуют один или несколько пробелов, за которыми следует слово «text». |
| ^d+(.d+)? | ^ определяет, что выражение должно начинаться с начала новой строки. d + соответствует одной или нескольким цифрам. ? делает утверждение в скобках необязательным. . соответствует «.», скобки используются для группировки. Соответствует, например, «5», «1,5» и «2.21». |
Capturing groups
Группы захвата(Capturing groups) — это способ рассматривать несколько символов как единое целое. Они создаются путем помещения символов, которые будут сгруппированы, в набор скобок.
Например, (dog) создает одну группу, содержащую буквы «d», «o» и «g».
Группы захвата нумеруются путем подсчета открывающих скобок слева направо. В выражении ((A) (B (C))), например, есть четыре такие группы —
Чтобы узнать, сколько групп присутствует в выражении, вызовите метод groupCount для объекта соответствия. Метод groupCount возвращает int, показывающий количество групп захвата, присутствующих в шаблоне сопоставителя.
Существует также специальная группа, группа 0, которая всегда представляет все выражение. Эта группа не включена в общее количество, сообщенное groupCount.
В следующем примере показано, как найти строку цифр из заданной буквенно-цифровой строки:
Это даст следующий результат:
Found value: This order was placed for QT3000! OK?
Found value: This order was placed for QT300
Found value: 0
Синтаксис регулярных выражений в Java
Вот таблица со списком всех синтаксисов регулярных выражений, доступных в Java:
| Subexpression | Соответствия |
|---|---|
| ^ | Соответствует началу строки. |
| $ | Соответствует концу строки. |
| . | любому отдельному символу, кроме новой строки. Использование опции m позволяет ему соответствовать и новой строке. |
| […] | любому отдельному символу в скобках. |
| [^…] | любому отдельному символу не в скобках. |
| A | Начало всей строки. |
| z | Конец всей строки. |
| Z | Конец всей строки, кроме допустимого конечного terminator. |
| re* | Соответствует 0 или более вхождений предыдущего выражения. |
| re+ | Соответствует 1 или более из предыдущего. |
| re? | Соответствует 0 или 1 вхождению предыдущего выражения. |
| re | Совпадает ровно с числом вхождений предыдущего выражения. |
| re | Соответствует n или более вхождений предыдущего выражения. |
| re | Соответствует не менее n и не более m вхождений предыдущего выражения. |
| a| b | Соответствует либо a, либо b. |
| (re) | Группирует регулярные выражения и запоминает сопоставленный текст. |
| (?: re) | Группирует без запоминания сопоставленного текста. |
| (?> re) | Соответствует независимому паттерну без возврата. |
| w | Слову из символов. |
| W | несловесным символам. |
| s | Соответствует пробелу. Эквивалентно [tnrf]. |
| S | без пробелов. |
| d | Соответствует цифрам. Эквивалентно [0-9]. |
| D | Совпадает с «не цифрами». |
| A | началу строки. |
| Z | концу строки. Если новая строка существует, она совпадает непосредственно перед новой строкой. |
| z | концу строки. |
| G | точке, где закончился последний. |
| n | Обратная ссылка для захвата номера группы «n». |
| b | Соответствует границам слов вне скобок. Соответствует возврату (0x08) внутри скобок. |
| B | границам без слов. |
| n, t, etc. | Сопоставляет переводы строк, возврат каретки, вкладки и т. д. |
| Q | Escape (цитата) все символы до E. |
| E | Завершает цитирование, начинающееся с Q. |
Обратная косая черта имеет предопределенное значение в Java. Вы должны использовать двойную обратную косую черту \, чтобы определить одну обратную косую черту. Если вы хотите определить w, то вы должны использовать \w.
Методы класса Matcher
Вот список полезных методов экземпляра — Index methods предоставляют полезные значения индекса, которые точно показывают, где совпадение было найдено во входной строке.
| № | Метод и описание |
|---|---|
| 1 | public int start() Возвращает начальный индекс предыдущего match. |
| 2 | public int start(int group) Возвращает начальный индекс подпоследовательности, захваченной данной группой во время предыдущей операции сопоставления. |
| 3 | public int end() Возвращает смещение после последнего совпадения символов. |
| 4 | public int end(int group) Возвращает смещение после последнего символа подпоследовательности, захваченной данной группой во время предыдущей операции сопоставления. |
Методы Study
Методы Study проверяют входную строку и возвращают логическое значение, указывающее, найден ли шаблон.
| № | Метод и описание |
|---|---|
| 1 | public boolean lookingAt() Пытается сопоставить входную последовательность, начиная с начала, с шаблоном. |
| 2 | public boolean find() Пытается найти следующую подпоследовательность входной последовательности, которая соответствует шаблону. |
| 3 | public boolean find(int start) Сбрасывает это сопоставление и затем пытается найти следующую подпоследовательность входной последовательности, которая соответствует шаблону, начиная с указанного индекса. |
| 4 | public boolean matches() Попытки сопоставить весь регион с паттерном. |
Методы замены
Методы замены являются полезными методами для замены текста во входной строке.
| № | метод и описание |
|---|---|
| 1 | public Matcher appendReplacement(StringBuffer sb, String replacement) Реализует нетерминальный шаг добавления и замены. |
| 2 | public StringBuffer appendTail(StringBuffer sb) Реализует шаг добавления и замены терминала. |
| 3 | public String replaceAll(String replacement) Заменяет каждую подпоследовательность входной последовательности, которая соответствует шаблону с данной строкой замены. |
| 4 | public String replaceFirst(String replacement) Заменяет первую подпоследовательность входной последовательности, которая соответствует шаблону с данной строкой замены. |
| 5 | public static String quoteReplacement(String s) Возвращает буквенную замещающую строку для указанной строки. Этот метод создает строку, которая будет работать в качестве литеральной замены в методе appendReplacement класса Matcher. |
Методы начала и конца
Ниже приведен пример, который подсчитывает, сколько раз слово cat (кот) появляется во входной строке:
Получим результат:
Match number 1
start(): 0
end(): 3
Match number 2
start(): 4
end(): 7
Match number 3
start(): 8
end(): 11
Match number 4
start(): 19
end(): 22
Этот пример использует границы слов, чтобы гарантировать, что буквы «c» «a» «t» не являются просто подстрокой в более длинном слове. Это также дает некоторую полезную информацию о том, где во входной строке произошло совпадение.
Метод start возвращает начальный индекс подпоследовательности, захваченной данной группой во время предыдущей операции сопоставления, а end возвращает индекс последнего сопоставленного символа плюс один.
Методы поиска(lookingAt)
Методы match и LookingAt пытаются сопоставить входную последовательность с шаблоном. Разница, однако, заключается в том, что для matches требуется сопоставление всей входной последовательности, а для lookingAt — нет.
Оба метода всегда начинаются с начала строки ввода. Вот пример:
Получим следующий результат:
Current REGEX is: foo
Current INPUT is: fooooooooooooooooo
lookingAt(): true
matches(): false
Методы replaceFirst и replaceAll
Методы replaceFirst и replaceAll заменяют текст, соответствующий заданному регулярному выражению. replaceFirst заменяет первое вхождение, а replaceAll заменяет все вхождения.
Вот пример, объясняющий их работу:
И теперь вывод:
The cat says meow. All cats say meow.
Методы appendReplace и appendTail
Класс Matcher также предоставляет методы appendReplacement и appendTail для замены текста.
Методы класса PatternSyntaxException
PatternSyntaxException — это непроверенное исключение, которое указывает на синтаксическую ошибку в шаблоне. Класс PatternSyntaxException предоставляет следующие методы, чтобы помочь вам определить, что пошло не так:
| № | метод и описание |
|---|---|
| 1 | public String getDescription() Получает описание ошибки. |
| 2 | public int getIndex() Получает индекс ошибки. |
| 3 | public String getPattern() Извлекает ошибочный шаблон регулярного выражения. |
| 4 | public String getMessage() Возвращает многострочную строку, содержащую описание синтаксической ошибки и ее индекс, ошибочный шаблон регулярного выражения и визуальную индикацию индекса ошибки в шаблоне. |
Примеры
Напишите регулярное выражение, которое соответствует любому номеру телефона.
Телефонный номер в этом примере состоит либо из 7 номеров подряд, либо из 3 номеров, пробела или тире, а затем из 4 номеров.
В следующем примере проверяется, содержит ли текст число из 3 цифр.
В следующем примере показано как извлечь все действительные ссылки с веб-страницы. Не учитывает ссылки, начинающиеся с «javascript:» или «mailto:».
Поиск дублированных слов.
b(w+)s+1b
b является границей слова и 1 ссылается на совпадение первой группы, то есть первого слова. (?!-in)b(w+) 1b находит повторяющиеся слова, если они не начинаются с «-in». Добавьте (?S) для поиска по нескольким строкам.
Поиск элементов, которые начинаются с новой строки.
(ns*)title
Также можете посмотреть официальную документацию тут.
Средняя оценка / 5. Количество голосов:
Спасибо, помогите другим — напишите комментарий, добавьте информации к статье.
Или поделись статьей
Видим, что вы не нашли ответ на свой вопрос.
17. Java — Регулярные выражения
Пакет java.util.regex предоставляется Java с целью сопоставления регулярных выражений с шаблоном. Регулярные выражения Java характеризуются существенным сходством с языком программирования Perl и очень просты в освоении.
В Java регулярные выражения представляют собой особую последовательность символов, позволяющую вам сопоставить или выявить другие строки либо их набор, опираясь на специализированный синтаксис в качестве шаблона. Они могут быть использованы для поиска, редактирования либо манипулирования текстом и данными.
Пакет java.util.regex исходно состоит из следующих трех классов:
Содержание
Группы сбора
Группы сбора представляют способ обращения с несколькими символами как с одной единицей. Они создаются путем размещения символов, которые предстоит сгруппировать, в серии круглых скобок. К примеру, регулярное выражение (dog) составляет отдельную группу, содержащую буквы «d», «o», и «g».
Группы сбора нумеруются посредством определения числа открывающих круглых скобок слева направо. Так, в выражении ((A)(B(C))) присутствуют четыре подобные группы:
Для определения числа групп, представленных в выражении, вызвать метод groupCount на объекте класса matcher в Java. Метод groupCount извлекает число типа int, отображающее количество групп сбора, представленных в сопоставляемом шаблоне.
Также имеется специальная группа, группа 0, которая во всех случаях представляет выражение в полном виде. Данная группа не включается в сумму, представленную методом groupCount.
Пример
Ниже рассмотрен пример регулярного выражения в Java, иллюстрирующий способ выявления строки цифр в представленных буквенно-цифровых строках.
В итоге будет получен следующий результат:
Синтаксис регулярных выражений
В Java регулярные выражения используют специальные символы. В следующей таблице представлены метасимволы доступные в синтаксисе регулярных выражений.
| Подвыражение | Обозначение |
| ^ | Соответствует началу строки. |
| $ | Соответствует концу строки. |
| . | Соответствует любому одиночному символу, за исключением новой строки. Использование опции m делает возможным соответствие новой строке. |
| [. ] | Соответствует любому одиночному символу в квадратных скобках. |
| [^. ] | Соответствует любому одиночному символу вне квадратных скобок. |
| A | Начало целой строки. |
| z | Конец целой строки. |
| Z | Конец целой строки, за исключением допустимого терминатора конца строки. |
| re* | Соответствует 0 либо более вхождений предыдущего выражения. |
| re+ | Соответствует 1 либо более вхождений предыдущего выражения. |
| re? | Соответствует 0 либо 1 вхождению предыдущего выражения. |
| re | Соответствует заданному n числу вхождений предыдущего выражения. |
| re | Соответствует n или большему числу вхождений предыдущего выражения. |
| re | Соответствует n как минимум и m в большинстве вложений предыдущего выражения. |
| a| b | Соответствует a или b. |
| (re) | Группирует регулярные выражения и запоминает сравниваемый текст. |
| (?: re) | Группирует регулярные выражения, не запоминая сравниваемый текст. |
| (?> re) | Соответствует независимому шаблону без возврата. |
| w | Соответствует словесным символам. |
| W | Соответствует символам, не образующим слова. |
| s | Соответствует пробелу. Эквивалент [tnrf]. |
| S | Соответствует непробельному символу. |
| d | Соответствует цифре. Эквивалент [0-9]. |
| D | Соответствует нечисловому символу. |
| A | Соответствует началу строки. |
| Z | Соответствует окончанию строки. При наличии новой строки, располагается перед ней. |
| z | Соответствует концу строки. |
| G | Соответствует точке, где оканчивается предыдущее совпадение. |
| n | Обратная ссылка на группу сбора под номером «n». |
| b | Соответствует границе слова вне квадратных скобок. Соответствует возврату на одну позицию (0x08) внутри квадратных скобок. |
| B | Соответствуют границам символов, не образующих слова. |
| n, t, etc. | Соответствует символам перевода строки, возврата каретки, табуляции, и т.д. |
| Q | Управление (цитирование) всех символов до символа E. |
| E | Окончание цитаты, открытой при помощи Q. |
Методы класса Matcher
Далее представлен список полезных методов экземпляра класса.
Методы индексов
Методы индексов представляют полезные значения индекса, которые демонстрируют точное количество соответствий, обнаруженных в вводимой строке.
| №. | Метод и описание |
| 1 | public int start() Возврат начального индекса к предыдущему совпадению. |
| 2 | public int start(int group) Возврат начального индекса к последовательности, захваченной данной группой в течение предыдущей операции установления соответствия. |
| 3 | public int end() Возврат позиции смещения следом за последним совпадающим символом. |
| 4 | public int end(int group) Возврат позиции смещения следом за последним символом к последовательности, захваченной данной группой в течение предыдущей операции установления соответствия. |
Методы исследования
Методы исследования производят анализ вводимой строки и возврат булевого значения, отображающего наличие либо отсутствие шаблона.
| №. | Метод и описание |
| 1 | public boolean lookingAt() Предпринимает попытку поиска соответствия вводимой последовательности в начале области с шаблоном. |
| 2 | public boolean find() Предпринимает попытку поиска следующей подпоследовательности в вводимой последовательности, соответствующей шаблону. |
| 3 | public boolean find(int start) Сброс данного поиска соответствия и попытка поиска новой подпоследовательности в вводимой последовательности, соответствующей шаблону с указанного индекса. |
| 4 | public boolean matches() Предпринимает попытку поиска совпадений во всей области с шаблоном. |
Методы замены
Методы замены представляют полезные методы для замены текста в вводимой строке.
| №. | Метод и описание |
| 1 | public Matcher appendReplacement(StringBuffer sb, String replacement) Производит нетерминальное присоединение и замену. |
| 2 | public StringBuffer appendTail(StringBuffer sb) Производит терминальное присоединение и замену. |
| 3 | public String replaceAll(String replacement) Заменяет каждую подпоследовательность в вводимой последовательности, совпадающей с шаблоном, указанным в замещающей строке. |
| 4 | public String replaceFirst(String replacement) Замещает первую подпоследовательность в вводимой последовательности, совпадающей с шаблоном, указанным в замещающей строке. |
| 5 | public static String quoteReplacement(String s) Возвращает литеральную замену Строки для указанной Строки. Данный метод производит сроку, которая будет функционировать в качестве литеральной замены s в методе appendReplacement класса Matcher. |
Методы start и end
Далее представлен пример, в котором производится подсчет количества раз, когда в строке ввода встречается слово «кот».
В итоге будет получен следующий результат:
Как видим, в данном примере используются границы слов с целью удостоверения в том, что буквы «c» «a» «t» не являются частью другого слова. Также отображаются определенные полезные сведения касательно нахождения совпадения в вводимой строке.
Метод start производит возврат начального индекса в последовательности, захваченной в данной группе в ходе предыдущей операции поиска совпадений, а end производит возврат индекса к последнему совпавшему символу, плюс один.
Методы matches и lookingAt
Оба метода matches и lookingAt направлены на попытку поиска соответствия вводимой последовательности с шаблоном. Разница, однако, заключается в том, что для метода matches требуется вся вводимая последовательность, в то время как lookingAt этого не требует.
Оба метода всегда начинаются в начале вводимой строки. Далее представлен пример, рассматривающий их функциональность.
В итоге будет получен следующий результат:
Методы replaceFirst и replaceAll
Методы replaceFirst и replaceAll производят замену текста, который совпадает с заданным регулярным выражением. Исходя из их названия, replaceFirst производит замену первого совпадения, а replaceAll производит замену остальных совпадений.
Далее представлен пример, поясняющий их функциональность.
В итоге будет получен следующий результат:
Методы appendReplacement и appendTail
Класс Matcher также предоставляет методы замены текста appendReplacement и appendTail.
Далее представлен пример, поясняющий их функциональность.
В итоге будет получен следующий результат:
Методы класса PatternSyntaxException
PatternSyntaxException представляет непроверяемое исключение, которое отображает синтаксическую ошибку в шаблоне регулярного выражения. Класс PatternSyntaxException представлен следующими методами, которые помогут определить вам ошибку.

